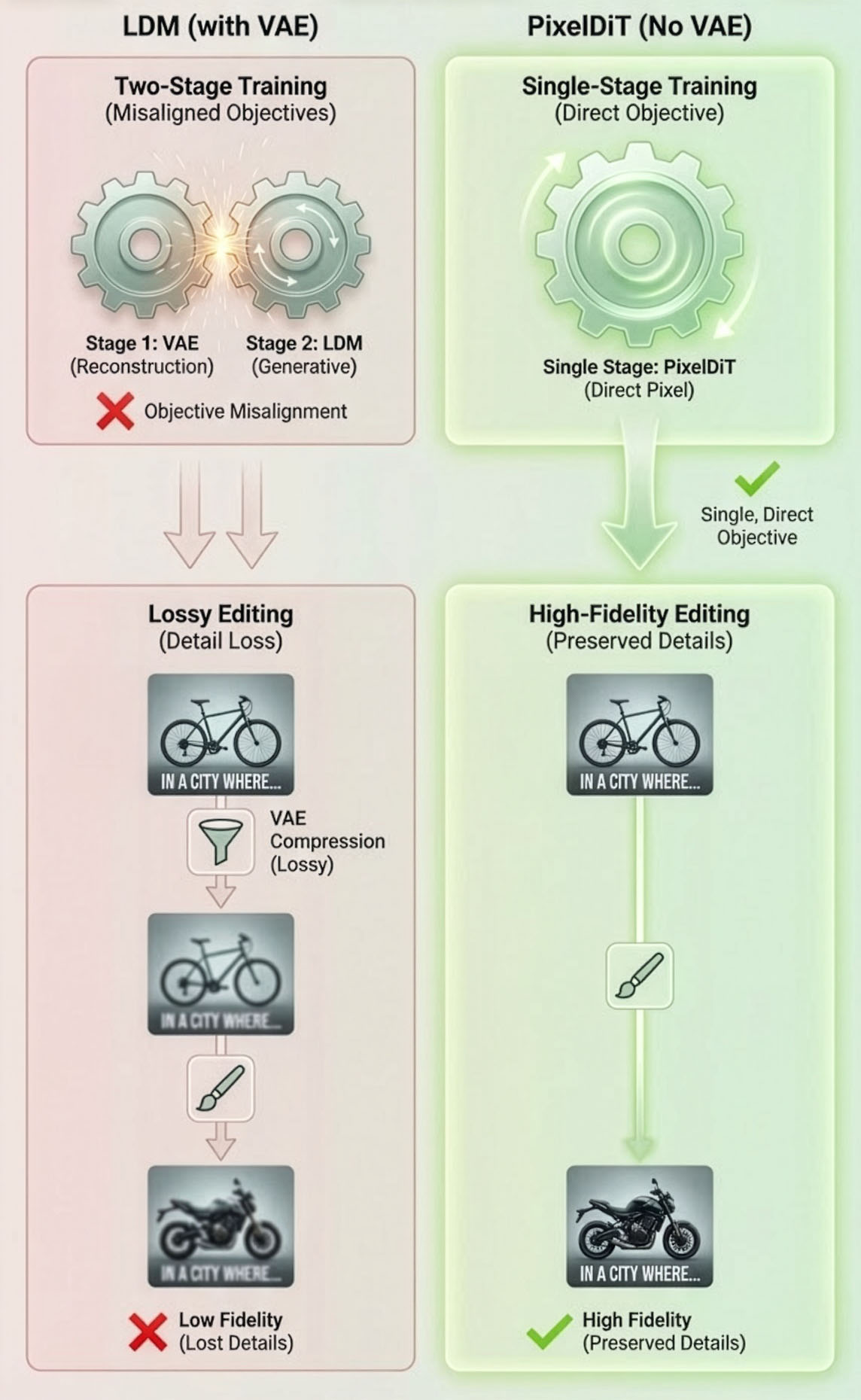
Latent Diffusion Models (LDMs) like Stable Diffusion rely on a Variational Autoencoder (VAE) to compress images into latents. This process is lossy.
- × Lossy Reconstruction: VAEs blur high-frequency details (text, texture).
- × Artifacts: Compression artifacts can confuse the generation process.
- × Misalignment: Two-stage training leads to objective mismatch.
Pixel Models change the game:
- ✓ End-to-End: Trained and sampled directly on pixels.
- ✓ High-Fidelity Editing: Preserves details during editing.
- ✓ Simplicity: Single-stage training pipeline.